
One can think that if one would keep on increasing the depth of a neural network, one can keep on achieving higher accuracy but that’s not the case as we have seen in the paper by Kaiming He et al.
Link to the paper - https://arxiv.org/pdf/1512.03385.pdf
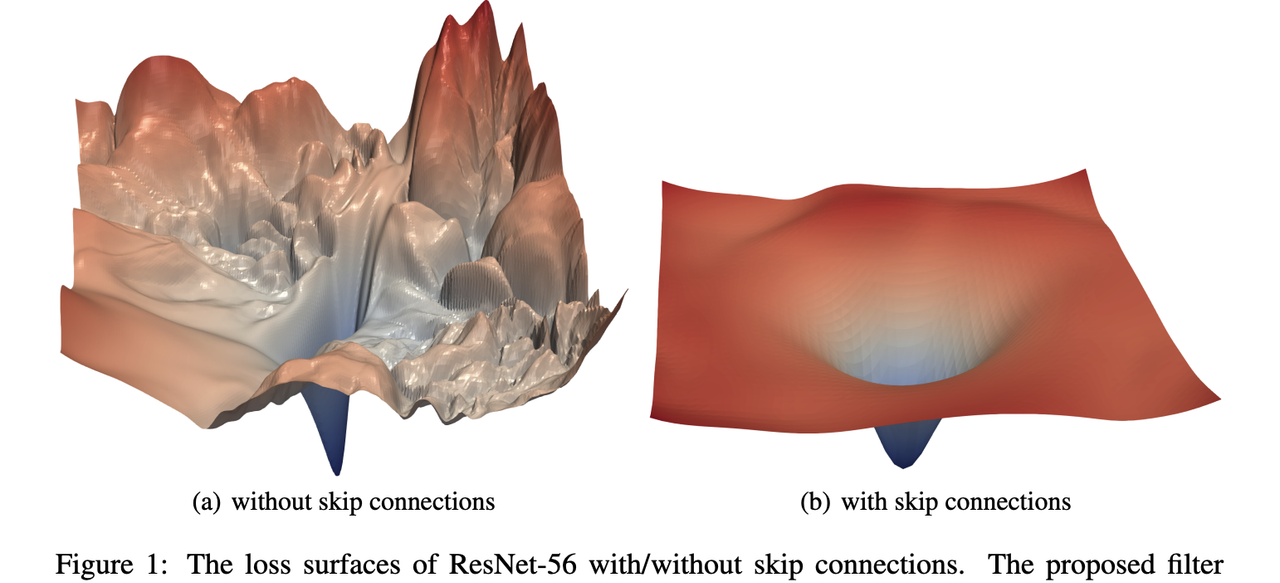
As we see in the first image itself, the training error for the deep network with 56 layers is worse than the training error with 20 layers.
The reason behind this stalling of the training of the neural network as we go deeper is the problem of the vanishng gradient.
During the backpropagation, the model has to adjust the weights and those adjustments are calculated accordin to the chain rule of derivatives. For many of the weights, these values come out as less than 1.
Also, these values are multiplied by a earning rate whose value is 0.1 > learning_rate > 0.0001, essentially a much smaller number. When we multiply more and more numbers that are less than 1, we get more small numbers and thus the weights of the earlier layers don’t get adjusted at all during the backpropagation.
For earlier layers, the chain rule will contain many more terms than the later layers and thus the earlier layers’ weight adjustement will consist of more multiplications which will result in a tiny number and according to:
new_weight = old_weight - learning_rate * result of chain rule
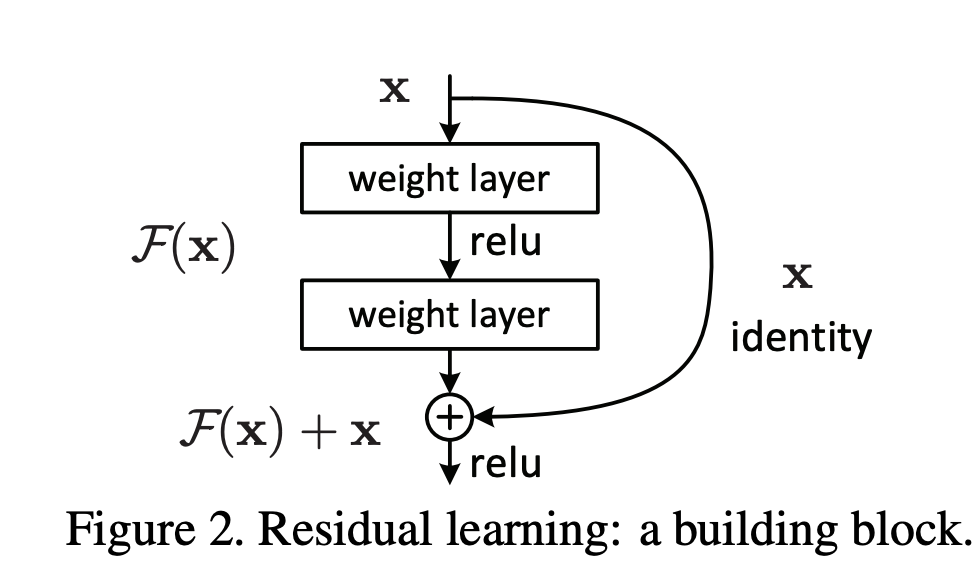
Resents are short for residual network and they contain a special block called the skip connection block after each convolution.
This skip connected block helps in avoiding the issue of vanishing gradient and the model is able to train not only faster but also with much greater accuracy.
We can see the loss surface of the two networks, one with the skip connection and the other without.
Goldstein, Xu, Li et all did some really great work for this paper of theirs in which they visualise the loss landscape of the neural networks.
Link to the paper - https://arxiv.org/pdf/1712.09913.pdf
In a normal convolution network, the layers are stacked on top of one another, while in Resnet, apart from the stacking, there is a skip connection that goes from the input to the output.
We have added the original input to the output of the convolution block via the skip connection, this will help during the backpropagation calculus and the partial derivative won’t reach a very small value and thus avoiding the issue of the vanishing gradient.
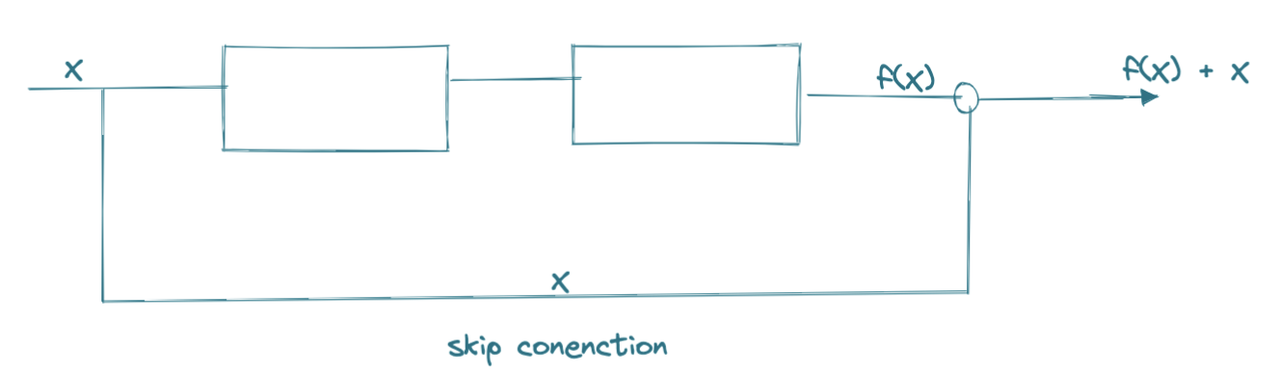
X is the input, f(X) is the output of the small network block and we have added the skip connection, so, at the adder, the value is f(X) + X.
If we can make f(X) = 0, then the output will at the adder will be Y = X, which is what we want = No error from the system and input gets recognised as the output(if not 0 then make f(X) as small as possible)
Note The first layer of the Resnet arch has stride 2 convolution. The vernacular 1x1 conv, 64 means filter size of 1x1 and 64 such filters; 3x3, 128 means 3x3 sized filter and 128 such filters.

As we can see, in the residual model, after 3 conv layers, the number of filters have changed from 64 to 128 which means we must have decreased the size of the image. The size shift at various times can be seen through the dotted connections.
Size of the image after each block is given by:
(n + 2P - f)/2 + 1
So, a 300 by 300 image after first layer of convolution with stride, s= 2, padding, f = 3, filter size, p = 7 becomes 150 by 150
As we move through the layers, the size keeps on decreasing.
One more thing about the dotted and solid skip conenctions, the dotted ones are called the convolution blocks while the solid ones are called the identity blocks.
The identity block is used when the input size = the output size i.e. the image doesn’t go through any size transformation. If the image has gone throguh the convolutions and also size transformations, in that case the input can’t simply be added via a skip connection because of disparity in the input and output sizes.
In this case, before feeding the value of x, it goes through a convolution block of its own to make the sizes consistent
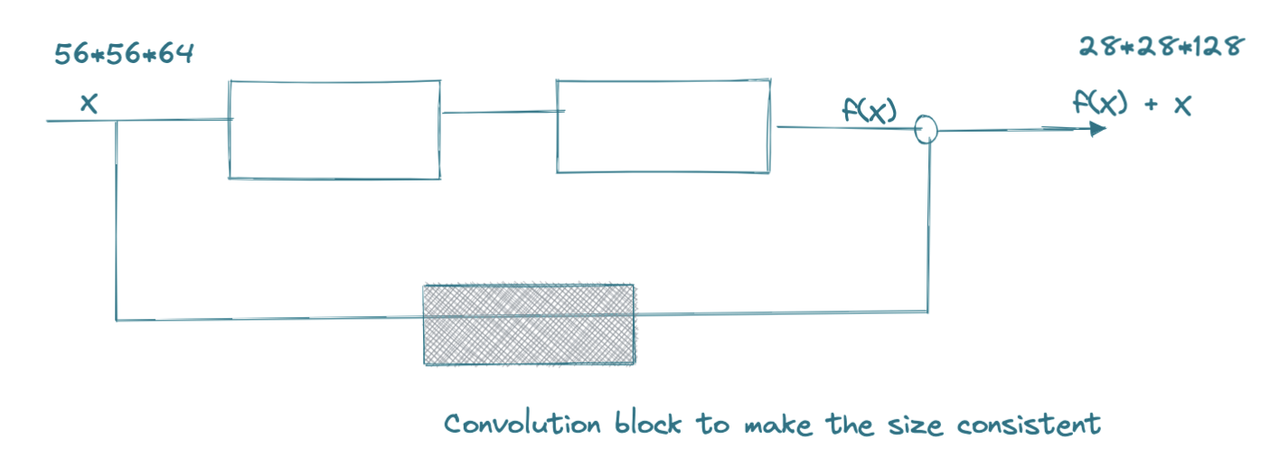
The convolution in the skip connection block generally is 1x1 filter size convolution.
That’s the architecture of the Resnet, it works while striving to make the f(X) = 0 and thus making, Y = X.