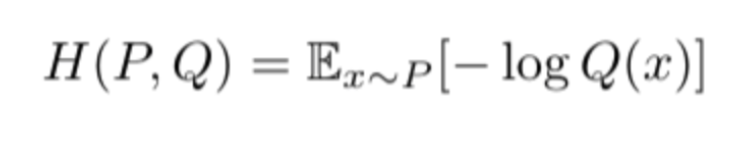This is an important function in deep learning, since we often want to ensure values are between 0 and 1.

The sigmoid function always outputs a number between 0 and 1.
This is an important function in deep learning, since we often want to ensure values are between 0 and 1.
It takes any input value, positive or negative, and smooshes it onto an output value between 0 and 1. It’s also a smooth curve that only goes up, which makes it easier for SGD to find meaningful gradients.
Cross-entropy loss is a loss function that has two benefits:
In binary case, one can use sigmoid for compressing the numbers between 0 and 1; then use sigmoid and 1-sigmoid as the prediction probabilities.
This won’t work for the multiclass classification such as MNIST digit, Pets or other datasets, so we can’t just take the sigmoid.
What we want is a method which will take all the numbers and squish them between 0 and 1 in a manner that the prediction across all the classes adds to 1. # Law of probability.
This function should reflect how strong and confident our prediction is.
Softmax is one such function. Just like sigmoid, it is an exponential based function.
Exponential is inverse of the logarithm, it is always positive, and it increases very rapidly.
Softmax = take exponent of the number / sum of all exponents of all numbers
The exponential has a nice property: if one of the numbers in our activations x is slightly bigger than the others, the exponential will amplify this (since it grows, well… exponentially), which means that in the softmax, that number will be closer to 1.
Intuitively, the softmax function really wants to pick one class among the others, so it’s ideal for training a classifier when we know each picture has a definite label. It may be less ideal during inference, as you might want your model to sometimes tell you it doesn’t recognize any of the classes that it has seen during training, and not pick a class because it has a slightly bigger activation score. I
F.nll_loss takes the softmax and then takes the negative.
NLL is the Negative Log Likelihood.
Cross entropy loss may involve the multiplication of many numbers. Multiplying lots of negative numbers together can cause problems like numerical underflow in computers. Therefore, we want to transform these probabilities to larger values so we can perform mathematical operations on them. Log does exactly this. It is not defined for numbers less than 0, and looks like this between 0 and 1:

Additionally, we want to ensure our model is able to detect differences between small numbers. For example, the probabilities of .01 and .001, these numbers are very close together—but in another sense, 0.01 is 10 times more confident than 0.001. By taking the log of our probabilities, we prevent these important differences from being ignored.
Log of a number approaches negative infinity as the number approaches zero. In ML models, since the result reflects the predicted probability of the correct label, we want our loss function to return a small value when the prediction is “good” (closer to 1) and a large value when the prediction is “bad” (closer to 0). We can achieve this by taking the negative of the log:
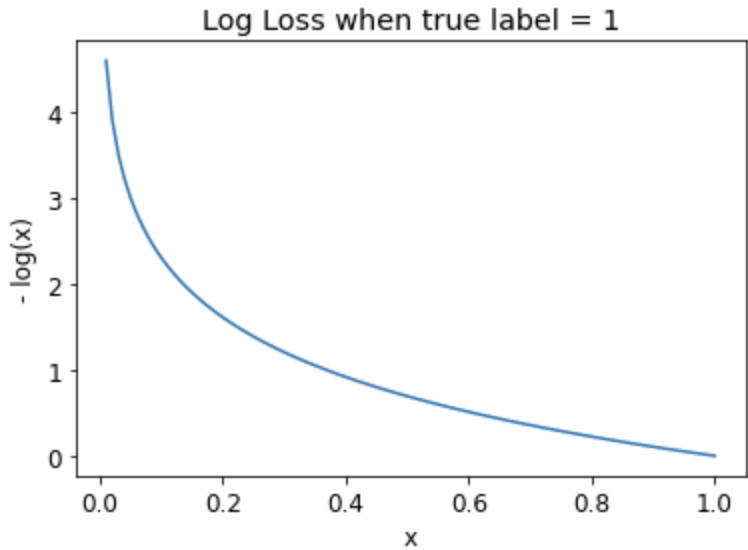
One benefit of using the log to calculate the loss is that our loss function penalizes predictions that are both confident and wrong. This kind of penalty works well in practice to aid in more effective model training.
You take the mean of the NLL to get the Loss value.
In pyTorch, the implementation is log_softmax and then nll_loss(log is taken with the softmax only and nll_loss only calculates the mean of the negative logs).
The gradient of the Cross entropy loss is linear, that means we won’t see sudden jumps or exponential increases in gradients, which should lead to smoother training of models.
It is called cross entropy because it is a measure of the difference between two probability distributions for a given random variable or set of event. It is also called log loss.
In Machine learning, it measures the difference between the actual values vs the predicted values.
Cross entropy finds its roots in the information theory and famous Claude Shannon’s equation
I(x) = -log₂P(x) ..where P(x) is probability of occurrence of x
It means lower the possibility of something happening, higher the information in that event/system e.g. all swans were considered white until Australia was discovered and there they saw the black swan for the first time. Thus the name black swan event = something highly improbable.
Entropy is from thermodynamics which means higher the randomness, higher is the entropy. High randomness means more information and thus the system has higher entropy.
In ML, we are also taking negative log, which means high value of negative log = more misclassification and thus higher total loss.(Similar to entropy)
We measure the loss by comparing our predictions with the real values, which is akin to comparing two probability distributions. A cross comparison of information contained in the two distributions and thus the name Cross Entropy.
Cross Entropy = minimize(Softmax + NLL) = maximize(LL)
LL is Log Likelihood, NLL is Negative Log Likelihood.
Equation of Cross Entropy for two prob. distributions P and Q.
E is the Expectation, while -log Q is logarithmic operation on one of the distribution.
Bin P = {2 red, 3 green, 4 blue}
Bin Q = {4 red, 4 green, 1 blue}
H(P, Q) = -[(2/9)*log₂(4/9) + (3/9)*log₂(4/9) + (4/9)*log₂(1/9)]